無事に就職先も決まったので、データサイエンティスト業務用のリハビリとして4月に読んだ書籍の感想を書く。

- 統計的因果推論の理論と実装
- RとStanではじめる ベイズ統計モデリングによるデータ分析入門
- StanとRでベイズ統計モデリング
- 仕組みと使い方がわかる Docker&Kubernetesのきほんのきほん
- 10年戦えるデータ分析入門 SQLを武器にデータ活用時代を生き抜く
- ビッグデータ分析・活用のためのSQLレシピ
- 確率思考の戦略論
- ロジカル・プレゼンテーション
統計的因果推論の理論と実装

以前にも一度読んだが再読した。一旦12章まで。
二周目だし余計なことを考えながら読む余裕があったのだが、余計なことというのはつまり統計的因果推論における因果概念と反実仮想概念の関係についてだ。因果と反実仮想にはどんな関係があるのか?
例えば「ラーメンを食ったら太る」という因果関係が本当に存在するのか、存在したとして一杯あたりの影響はどのくらいかを定量的に見積もる実験をやりたいとする。このとき、理想的にはAさんを一人連れてきて「Aさんが2024年5月7日の昼食にラーメンを食ったパターン」と「Aさんが2024年5月7日の昼食にラーメンを食わなかったパターン」でその後の動向を比べることが望ましい。
逆に望ましくない実験は? 「Aさんが2024年5月7日の昼食にラーメンを食ったパターン」と「Aさんが2024年5月8日の昼食にラーメンを食わなかったパターン」を比較するのはダメだ。「Aさんが2024年5月7日の昼食にラーメンを食ったパターン」と「Bさんが2024年5月7日の昼食にラーメンを食わなかったパターン」を比較するのもダメ。
何故なら日時や対象者が変わってしまうと、太ったり太らなかったりした原因がラーメンなのかその他の体質や環境なのかわからなくなってしまうからである。厳密にラーメンという原因のみが太ったという結果をもたらしたのかを知るためには、ラーメンを食ったか否か以外の部分は全て完全に一致していなければならない。
だが、Aさんが2024年5月7日の昼食にラーメンを食い、かつ、同時に食わないことは現実的に不可能である。そういうわけで、厳密な因果推論は測定不可能な反実仮想を要求する。だから色々な仮定を置いたり数式を弄ったりすることでどうにかして疑似的な反実仮想を作り出すことが当面の目標になる。
例えば一つのやり方として、「双子みたいなやつを連れてくる」という方向性が考えられる。完全には一致しないとしても、ある程度は似通ったステータスのやつを確保できれば一人にはラーメンを食わせて一人には食わせずに比べれば疑似的な反実仮想と見做してヨシとできるだろう。とはいえ、実際には双子がいる人は多くないし測定可能なパラメタを全て合わようとするのはまだだいぶしんどいので、「このスコアが一致していればだいたい同一人物扱いでいけるはず」みたいなスコアが出せると嬉しく、それが傾向スコアと呼ばれるものだったりする。
補足529:ラフに言えば、傾向スコアとはラーメンを食う確率のこと。「ラーメンを食う頻度が同じやつはラーメンに対して同じようなスタンスのやつだろう」と見做すことは直感的にもそれほどおかしくない。
ここまでの話は無作為性と結び付けて論じることもできる、というか、本来の統計学の意図からするとそちらの方が正道である。全く恣意的でないことを示す無作為性と、逆に完全な恣意性である類似性という、一見すると相反する概念が因果分析においては親和すると捉えても面白い。
これもラフに言えば「作為的に類似させた集団内での選択は無作為とみなしやすい」という、作為と無作為の脱構築のようなイメージが背景にある。例えば成績やら容姿やら体力やらが上から下までバラけたクラスで委員長を一人指名したら(もし本当は無作為に指名していたとしても)「あいつは顔が良いから選ばれたのだ」などという疑念を呼ぶが、最初から同じような生徒しかいないクラスでは誰を指名しても「まあランダムに選んだのだろう」と納得されやすいのである。
ちなみに分析哲学領域でも因果性が反実仮想と結びつくことは多いが(とりわけ陽にパラレルワールドを措定する可能世界論で顕著)、Rubin流のように統計的な無作為性と関連付ける理論があったかどうかは自信がなく、どちらかと言うとDAGのようなイメージで介入を扱うPearl流の方が親和性が高いような気がする。統計的因果推論がもう少しわかってきたら、RubinとPearlを踏まえて分析哲学的因果推論をちゃんと読んでもいいかもしれない。
RとStanではじめる ベイズ統計モデリングによるデータ分析入門
")
MCMCを用いたベイズ統計モデリングをRとStanで実装する本。
MCMCとベイズは理論の知識だけ知っていて実際にコードで触るのは初めてだったが、かなり面白かった。そもそも手計算ではなく計算機を前提とした実践に強い手法なので、実際にコーディングした方が面白いのは当然ではある(紙面で見ていてもイマイチわからない)。
ベイズ統計によるパラメタ分布推定はデータからオートマチックに更新を行えるためにモデリング(尤度関数設計)の柔軟性が高い一方、現実的には表式が複雑になりすぎて分布を正規化する積分計算ができず、結局正しい分布が得られないという弱点がある。そこに「正確な分布の表式はわからなくてもサンプリングだけはできる」というMCMCが登場し、「解析的には知らんけど使う分には問題ないからこれでいいでしょ」と解決されるわけだ。応用工学系の出身だからそういうゴリ押し解決好き。
実践的な手法としては、ベイズ統計モデリングは定性が強い古典統計学と定量が強い機械学習の中間に位置している。古典統計学は定性的な解釈を厳密に行えるが、あまりにも厳密すぎるが故に定量的に言えることが少ない弱点がある(「帰無仮説が棄却できない」とは要するに「よくわかりません」のかっこいい言い回しであることが知られている)。一方、機械学習は数値的な結論がはっきり出る代わりにブラックボックス化したモデルの解釈が困難であり定性的な分析には向かない。その点、ベイズ統計モデリングは定性的なメカニズム(モデリング)と定量的な推定結果(MCMCサンプル)を両立できるバランスの良いポジションにいる。
補足530:ベイズ統計モデリングも機械学習に含んでもよいのだが、ここで言っている機械学習というのは主にNNとかを想定した「いわゆる機械学習」というニュアンス。
ベイズ統計学がMCMCという後ろ楯を得たのは最近……では別にないにせよ、少なくとも使いやすいツールであるStanが発展したのはここ10年くらいのようだ。計算機が強力になりツールが普及したことで実践方面で起きた認識アップデートとして、共役事前分布がオワコンになっているらしいことは興味深い。共役事前分布を使うと事後分布の表式が綺麗になるので手計算では便利なのだが、汚い事後分布でもMCMCを使って力業で扱う技法が確立された以上、別にモデリングとして有利なわけでもない共役事前分布を使うインセンティブは薄くなる。
ベイズ統計学自体の話が長くなったが、この本は入門者向けに丁寧に書かれた良著だった。各チャプター内の各章ごとにテーマ、目的、意図、概要、流れみたいなものをはっきり書いているのが親切でありがたい。全体的に「とりあえず触ってみよう!」というわかりやすさ重視であり、細かい事前分布やパラメタ調整も割と天下り式で導入されたり、簡易版実行環境であるところのbrmsに寄り道したりするのは長所でも短所でもある。
ただ「入門目的なので頻度主義との比較には立ち入らない」と冒頭で明言するなど、理論の詳細についても深入りせず流している部分が多いため(それ自体は一つの誠実な選択だと思うが)、統計学に詳しくない初学者は理論については他でカバーした方が良いかもしれない。例えばパラメタの事後分布とデータの事後予測分布が理論上でどう異なるのかをグラフから理解するのはほとんど不可能に近い。大抵のパラメタのサンプル平均は予測データのサンプル平均となまじ一致してしまうだけに、散布図で見るとそれぞればらつきが違うサンプル群二つくらいにしか見えないのだが、理論的にはそもそも扱っている確率変数自体が全く異なるという罠がある。
StanとRでベイズ統計モデリング
")
上の本と同じくStanとRでMCMCによるベイズ統計モデリングをやる本だが、こちらはタイトルに入門と付いていないだけあって、もう少しレベルが高いバージョン。説明自体は一から行っているので、やる気があればこちらから入っても問題なさそう。
体験入学ではなく実践的な活用を見越しているため、具体的な意思決定や対処の方法まで厚くページが割かれているのが嬉しいところ。モデリングの現実的な手順や考え方や悩みどころ、収束しない場合の対処法など、泥臭く知見を色々教えてくれる割には章立ては整理されていて説明がわかりやすい。きちんとStanを扱うのであればこの本に目を通すと通さないとでは効率が大きく変わってきそうだ(ショートカット!)。
反面、細かいコードの記載は割と飛ばされがちなのでその辺りは自分でフォローできる中級者向けではある(特に図示周り)。が、作者のGitHubページに演習問題の解答を含めて省略されたコードが全て記載されているのでそちらを見ればあまり困ることはない。
仕組みと使い方がわかる Docker&Kubernetesのきほんのきほん
")
欲しいものリストから頂きました。ありがとうございます。
タイトル通りDockerのきほんがわかる良著。俺は環境構築を主導するポジションではないので情シスあたりに「今すぐDockerを入れられますか?」と聞かれて「ウッス!」とか言ってるだけだと思われるが、そういう現場まで含めてどんな人にはどんな知識が必要なのかを整理して書いてあるのが嬉しいところ。
完全無知勢向けに説明の厳密さや情報量をだいぶ端折った上で豊富なイラストと共にとりあえず触ることを重視して必要なコードも全掲載しているタイプの優しい技術入門書であり、特にコンテナとかOSの階層図がいちいちデカデカ入るのは実際かなりありがたい。モジュール化を旨として発展してきた情報技術にはありがちなことだが、コードにせよシステムにせよなんかラッパーみたいなやつが階層を作っているときに今どこの階層で何の話をしているのかわからなくなることは多い。
また、Docker自体は別にサーバー管理システムではないにせよ、最もよくDockerが使われるのはサーバ構築ということでサーバーを立ててみる体験ができるのもよかった(ローカルホスト)。サーバークライアントの知識自体は知っていたが具体的な手順はさっぱりだったのでその辺りの質感は初めて得られた。
ただ一応の注意点として、基本的にはDockerの本で、Kubernetesについてはほんのオマケ程度しかない。Dockerの説明には7章割かれているのに対してKubernetesは1章のみ、それも最終的には「素人には難しいのでプロに外注した方がいい」という結論に落ち着く。それ自体は誠実な説明として勉強になるにせよ、タイトルで並列するのは若干盛っている印象を受けないこともない(「きほんのきほん」だからセーフか?)。
10年戦えるデータ分析入門 SQLを武器にデータ活用時代を生き抜く
")
別に全然悪くはないけどまあという感じのSQL本。
2010年代前期~中期くらいによくあった典型的なビジネス向けデータ分析書で、「これから皆でデータ活用していこうぜ」という前のめりな空気感が熱く漂っているが、データ利活用が急速に普及した今から見ると普通のことしか書いていない印象になってしまう。技術的な内容もSQLの標準的な使い方解説に留まっていて既知の事柄が多い。
ただこの本は2015年刊行なので、タイトル曰く「10年戦える」ということはこれで戦えるのは2025年までということでもあり、確かに保ってあと1年くらいかなという寿命を正確に申告しているのは偉い。
ビッグデータ分析・活用のためのSQLレシピ

大量のSQLクエリを運用ベースで紹介している凄い本。
「SQLで書けることの把握」と「SQLですべきことの把握」は別のスキルであり、大抵のSQL解説書では前者メインでついでに後者にも触れるバランスだが、この本では後者をメインにして前者を適宜フォローする設計になっている。
紹介しているクエリごとに分析意図や可能な施策について逐一掘り下げているところが単なるSQLの解説と一線を画しているポイントだ(逆にSQLの文法や構文自体にはそこまで力が入っているわけではないため、全くの初学者は他の適当な入門書を一冊読んでからの方がいいかもしれない)。特に6章以降でユーザーの回遊状態などの見方についての考え方込みで具体的に解説されているのが非常に良かった。DMMの人が書いているし、ちょっと前にお題箱に来てたKPI分析をしたいゲームプランナーの人(お題箱833→■)はこれを読むといいと思います。オススメ。
ただ内容的には相当な良著なのだが、タイトルはあまりよくない気がする。タイトルから期待する内容と実際の内容が乖離しているから、というのも、タイトルには「ビッグデータ」と冠しているが、分散管理や非構造データのようなビッグデータ特有の話(いわゆる「3つのV」周り)は全く扱っておらず、むしろマスター・トランザクション・ログなどの典型的で地味なテーブルデータを対象としているからだ。それどころか「ビッグデータがなくても手元のデータで始められることはたくさんある」というスタンスであり、これからデータ分析を始める担当者や組織に向けた地道なアドバイスにわざわざ一章を割いている。バズワードだしビッグデータってつけた方が売れるんじゃねというノリだったのではないかなどと邪推してしまう感は否めない。
確率思考の戦略論
")
再読。だいぶ前に読んだときは「大量の自慢がノイズでいけすかない」という印象だったが、今読むと「ちゃんとした理論を元にして地に足の付いた実績エピソードでエビデンスを確保している」という風に印象が全く変わっていて加齢の影響を感じた(昭和オッサン構文で繰り出される武勇伝は未だに鼻につくが……)。
数学的には、言ってしまえばマーケティング用の購買モデルとして負の二項分布を据えたというだけの話ではある。負の二項分布とは確率pで成功する事象がm回成功するまでにn回失敗する確率を示す分布であり、これを購買モデルに応用すると、一定確率pで他社製品を購入する消費者全体がm回他社製品を買うまでにn回自社製品を買う確率が求まり、要するに売れ行きの見込みが立つ(勝ち馬拡大項を加えたりカテゴリを二重化したりモデルのバリエーションも紹介されているが根幹は同じ)。
ただしそのようなモデルを紙の上で作ったあとに実際のビジネスに繋げるためにはやるべきことが無限にある。そもそも「あるカテゴリーの商品を購入する際に製品ごとの選好度合いに応じて各製品を確率的に選ぶ」という仮定が実際の購買行動と一致したリーズナブルなものか確認しなければならないし、更に分布を構成するパラメタがビジネス上のKPIとしては何に対応するのかを特定し、最後にビジネス上で何をすればパラメタを操作できるのかを戦略立案しなければならない。これらは紙の上だけではどうにもならない、実際にやるしかない領域であり、理論とビジネスの橋渡しに成功した事例を示す価値はとてつもなく大きい。
あと統計的な内容についての備忘録を一応書いておく(ここから先は普段なら補足に回す内容だが、思ったより話が長くなって字が小さいと読むのがしんどいので補足にしなかった)。
一般にポアソン分布のパラメタがガンマ分布に従うときに負の二項分布が導かれることがよく知られている。数式を書くのは面倒なのでなるべく省エネ表記すると、要するにこの等式が成り立つ。
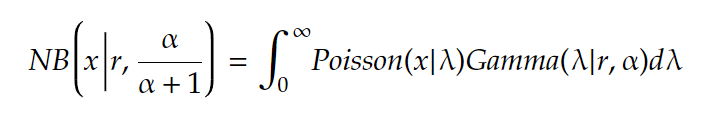
数式的な証明も有名だが、ネットで見つけた中だと特に以下の二記事がわかりやすかった(一つ目は記事中盤のアニメーションが秀逸、二つ目は式変形が平易でわかりやすい)。
ただ、この数式を日本語に翻訳したときに何故成り立つのかという自然言語による証明(念のための注:数学にそんな概念はない)がネットを探しても見つからなかったのでここに書いておく。別にこれに限ったことでもないのだが、数式で証明しただけでは形式的に正しいことしかわからないので理解としては片手落ちで、日本語に翻訳したときに意味が通る形で説明できなければ理解したことにならないと個人的には考えている。
まず両辺の意味を日本語に翻訳する。NBとPoissonとGammaの確率分布としての標準的な解釈は以下の通り。
- 左辺:確率α/(α+1)で成功する試行がr回成功するまでにx回失敗する確率
- 右辺:「平均間隔1/αで生起する事象がr回起こる時間の分布」に従って生起するλを平均回数とする事象がx回生起する確率
左辺は読めばわかるが、右辺ではポアソン分布とガンマ分布の入れ子がそのまま日本語の入れ子になっていて相当わかりづらい。今から両辺を(数式ではなく)日本語で嚙み砕くことで(数式ではなく)日本語として等価であることを示す作業をやるが、日本語ではαやrはあまり使わないので適当にα=10、r=100としておく。
- 左辺:確率10/11で成功する試行が100回成功するまでにx回失敗する確率
- 右辺:「平均間隔1/10で生起する事象が100回起こる時間の分布」に従って生起するλを平均回数とする事象がx回生起する確率
まず天下りで言ってしまうと、右辺の「平均間隔1/10で生起する事象」とは要するに「成功」の事だ。つまり「平均間隔1/10で生起する事象が100回起こる時間」とは要するに「成功が100回起こる時間」のことであり、左辺に書いてある「試行が100回成功するまで」と一致する。
そして左辺によると試行の成功確率は10/11らしいので、失敗は成功の10倍起こりにくいことがわかる。つまり成功が平均間隔1/10で生起するならば、失敗は平均間隔1で生起する。言い換えると、失敗は単位時間あたり平均1回起こるということでもある。だから失敗の平均回数と試行時間は一致する(ここが最大のポイント)。よって「成功が100回起こる時間」はそのまま「『成功が100回起こる時間』に起きる失敗の平均回数」と読み替えてもよい。
ここまでの解釈を踏まえて右辺の「『平均間隔1/10で生起する事象が100回起こる時間の分布』に従って生起するλを平均回数とする事象」という記述を眺め直すと、「『【成功が100回起こる時間】に起きる失敗の平均回数の分布』に従って生起するλを平均回数とする事象」と読み替えられ、これは要するに「成功が100回起こる時間で起きる失敗」のことである。結局、右辺は「成功が100回起こる時間で失敗がx回生起する確率」という意味になり左辺と一致する。■
標準的な解釈としてはガンマ分布が「時間」を生成する関数であるにも関わらず、ガンマ分布から生起したサンプルが「平均発生回数」を示すポアソン分布のパラメタとして解釈できる背景には、「失敗は単位時間あたり平均1回生起するので、時間と平均回数の値は一致する」というギミックがあったことがポイント。
ロジカル・プレゼンテーション

データサイエンスではないが関連するので読んだ。
若干ありきたりにも思えるタイトルを警戒しながら手に取ったが、浅いビジネス書や研修資料とは一線を画した明確な良著だった。このタイプの本を読みたいならまず最初にこれを読めと断言できる一冊。
この手の本にしては画期的に解像度が高く、かつ体系的であることが素晴らしい。主題である「提案の技術」を散発的なアドバイス集として語ることを徹底的に拒否しており、逆に頂点から演繹する形で樹形図状に体系的な論理を展開している。例えば「4C分析」だの「MECE」だの「仮説思考」だのというビジネス書によく書いてある(ビジネス系Youtuberが適当に解説している)諸々の概念が、体系上でどの位置に入ってきてそれを使う目的は何なのかというようにポジションと合目的性が徹底的に言語化される。
かといって体系の完成度だけを重視した机上論に陥るわけでもなく、むしろ逆で、天下りではなく合目的的に演繹しているために細かい留保にも隙がない。例えば「MECEとか言うけど、現実の複雑なビジネスシーンで状況がMECEに分類できることなんて実際ないよね」とか「ファクトベースとか言うけど、現実の無限にある要素をどれだけ調べても100%の結論が出せることなんて実際ないよね」というような現実的な状況に対する処方もはっきり述べている。
補足531:手前味噌で恐縮だが、俺も同じマインドで前に就活の記事(これ→■)を書いてバズったので作者の姿勢には非常に共感できる。つまりビジネスには本来であれば有益なはずの概念やアドバイスが「そういうものだから」という本質を捉えていない低解像度な状態で流通していることが割とよくあって、それを合目的的に言語化することには強い需要があるのだ。
この手の本にしては珍しくあとがきでの鬱陶しい自分語りがないのも好印象。各章ごとに小説仕立てのストーリーが挿入されているがそれもビジネス書によくある作者の武勇伝ではなく、本論の中で回収するための具体事例として過不足なく精密に設計されている。
補足532:こういう偏執的な体系理論を設計するやつは絶対に東大か京大だろうな~と思って作者情報を見たらやはり東大を中退して京大を出ていた。
この本では繰り返し主張されていることだが、「論理的に正しいだけでは片手落ちで、相手や状況に合わせて伝える技術がなければ意味がない」という考え方は学生時代ならあまり納得しなかったと思う。「論理的に正しいことがすなわち客観性の担保なのであり、理解できないことを咎めはしないまでも理解する方向に相手が努力すべきだ」くらいには思っていたはずだが、加齢の影響で今では「伝え方って大事だよね」と普通に頷ける。
確かに理想的な平衡状態では論理的に正しいだけでヨシとなってほしいものだが、意外と世界の時間軸は短い。人間の一生も社会の趨勢も大域最適解に到達するには時間が足りなすぎるため、局所的な対症療法は常に必要なのである。